Tutorial 3: Increasing the data resolution#
Author: Hannu Parviainen Edited: 11 February 2026
So far, we’ve learned how to construct a transmission spectroscopy analysis with ExoIris from scratch, create a new analysis from an existing one, and add detail to a wavelength region of interest by adding radius ratio knots. Here, we see how to do a study with a higher data resolution starting from an existing lower-resolution analysis. However, since the Tutorial 1 knot resolution is already relatively low compared to the intrinsic data resolution (R=100), we also increase the radius ratio knot resolution (as in Tutorial 2) to make the example a bit more interesting.
[1]:
%run ../setup_multiprocessing.py
[2]:
import matplotlib.pyplot as plt
from multiprocessing import Pool
from xarray import load_dataset
from numpy import array, geomspace, linspace, inf
from matplotlib.pyplot import subplots, setp
from exoiris import ExoIris, TSData, load_model, clean_knots
plt.rc('figure', figsize=(12,4))
pargs = dict(figsize=(13, 7), res_args=dict(pmin=5, pmax=95), height_ratios=(0.4, 0.6),
trs_args=dict(xscale='log', ylim=(2.0, 2.23), xticks=[0.6, 0.88, 1.16, 1.44, 1.72, 2.0, 2.30, 2.8]))
ExoIris setup#
Load the low-resolution model#
We again begin by loading an existing analysis from Tutorial 1.
[3]:
ts = load_model("01a.fits", name='03a')
ts.plot_setup();
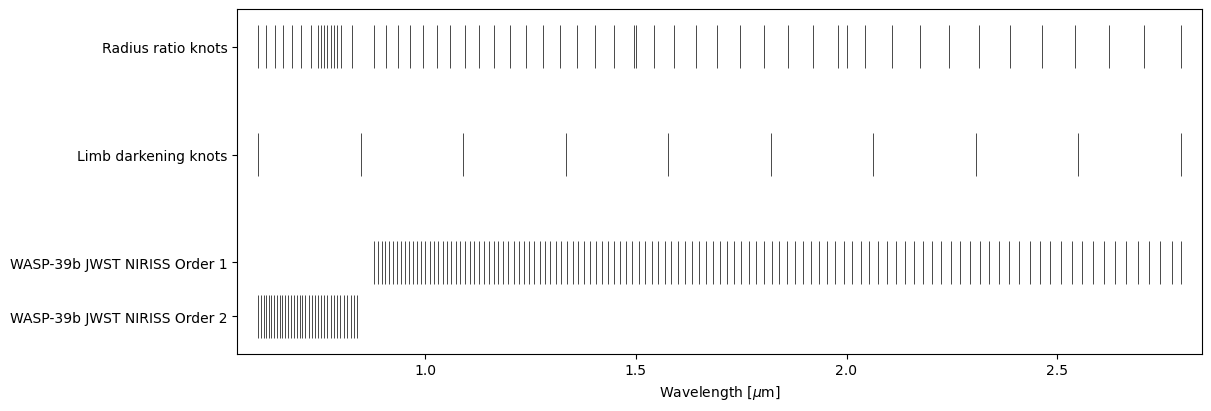
Data setup#
Next, let’s read in the data as in Example 1, but bin it to R=300 instead of R=100. We could also skip the binning altogether and use the native data resolution, but this will still be a bit slower.
[4]:
def read_data(fname, name="", noise_group: str = 'a', n_baseline: int = 5):
with load_dataset(fname) as ds:
return TSData(time=ds.time.values, wavelength=ds.wavelength.values, fluxes=ds.flux.values, errors=ds.error.values,
name=name, noise_group=noise_group, n_baseline=n_baseline)
d1 = read_data('data/nirHiss_order_1.h5', "WASP-39b JWST NIRISS Order 1", noise_group=0, n_baseline=2)
d1.crop_wavelength(0.86, 2.8)
d1.mask_outliers(8)
d1.mask_transit(t0=2459783.5015, p=4.0552842, t14=0.13)
d1.normalize_to_poly()
d2 = read_data('data/nirHiss_order_2.h5', "WASP-39b JWST NIRISS Order 2", noise_group=1, n_baseline=2)
d2.mask_outliers(5)
d2.crop_wavelength(0.6, 0.84)
d2.mask_transit(ephemeris=d1.ephemeris)
d2.normalize_to_poly()
db = d2.bin_wavelength(r = 300, estimate_errors=True) + d1.bin_wavelength(r = 300, estimate_errors=True)
for d in db:
d.estimate_average_uncertainties()
fig = db.plot(ncols=2)
fig.tight_layout()
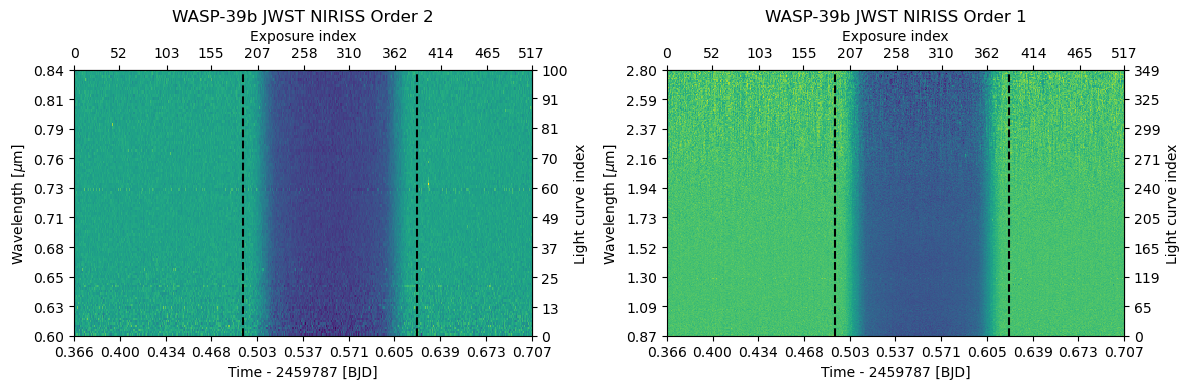
After which we can simply replace the old data set with the new one using the ExoIris.set_data method.
[5]:
ts.set_data(db)
ts.plot_setup();
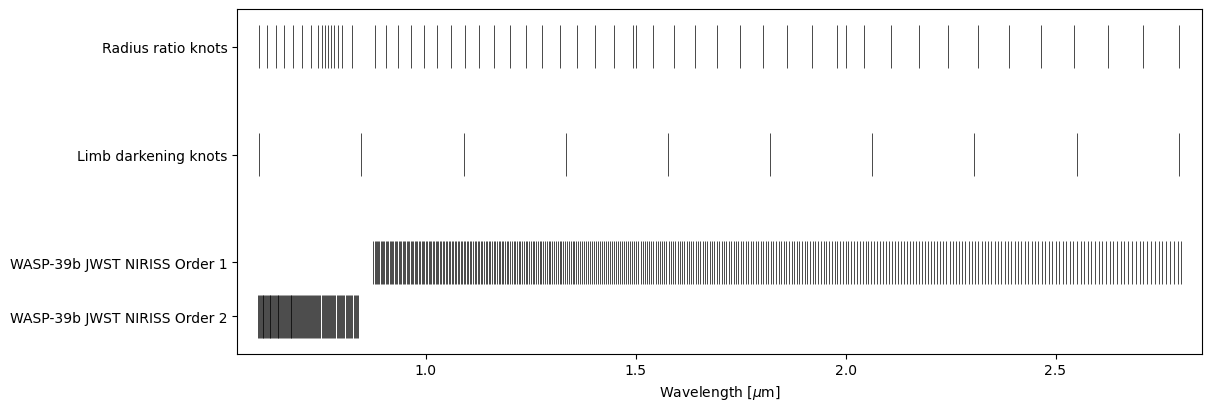
And that’s it!
We could continue the analysis with a short global optimisation followed by MCMC sampling as in Example 2, but let’s complicate things a bit and also increase our radius ratio knot resolution by combining four knot grids. Note that we can make the start and end points of the grids match because the overlapping knots are cleaned automatically.
[6]:
from numpy import c_, r_
knots = r_[geomspace(0.61, 0.768-0.02, 10),
linspace(0.768-0.020, 0.768+0.02, 9),
linspace(0.855-0.055, 0.855+0.055, 13),
geomspace(0.855+0.055, 2.8, 120)]
[7]:
ts.set_radius_ratio_knots(knots)
knots = ts.k_knots.copy()
m = (knots > ts.data[0].bbox_wl[1]) & (knots < ts.data[1].bbox_wl[0])
ts.set_radius_ratio_knots(knots[~m])
ts.plot_setup();
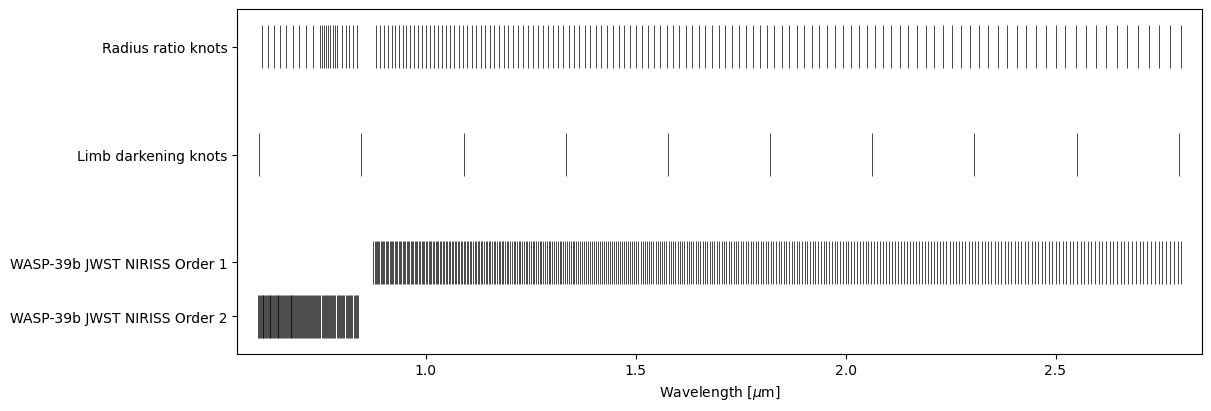
Fitting#
Now that the model and data have been set up, we can soon again continue by performing a round of global optimisation and then posterior sampling. First, however, we need to check the number of model parameters, ts.ndim. Increasing the data resolution does not increase the model resolution, but increasing the number of radius ratio knots does, and the emcee sampler requires that our parameter vector population size (number of walkers in emcee) is at least twice the number of model
parameters.
[8]:
ts.ndim
[8]:
174
So, we need a population size of at least 2 x 174 = 348. We create the initial population for the optimiser using the ExoIris.create_initial_population method by drawing 400 random parameter vectors from the saved low-resolution model posterior sample and by adding some noise to the population.
[9]:
x0 = ts.create_initial_population(400, 'mcmc', add_noise=False)
After which we start the optimisation. Note that the ExoIris.fit method has two very similar arguments: population and initial_population. The difference is that the population argument resets the optimiser and starts from the given population, while the initial_population is used only if the optimiser hasn’t been started yet (or hasn’t been reset). This allows you to set the initial population and run the ExoIris.fit method multiple times with the same arguments so that
each run continues from the previous state (instead of always starting from the initial_population what would happen with the population argument).
[10]:
def lnpostf(pv):
return ts.lnposterior(pv)
pool = Pool(8)
[11]:
ts.fit(niter=10, pool=pool, lnpost=lnpostf, initial_population=x0)

[12]:
ts.fit(niter=10_000, pool=pool, lnpost=lnpostf, initial_population=x0)

[13]:
ts.plot_fit('fit', **pargs);
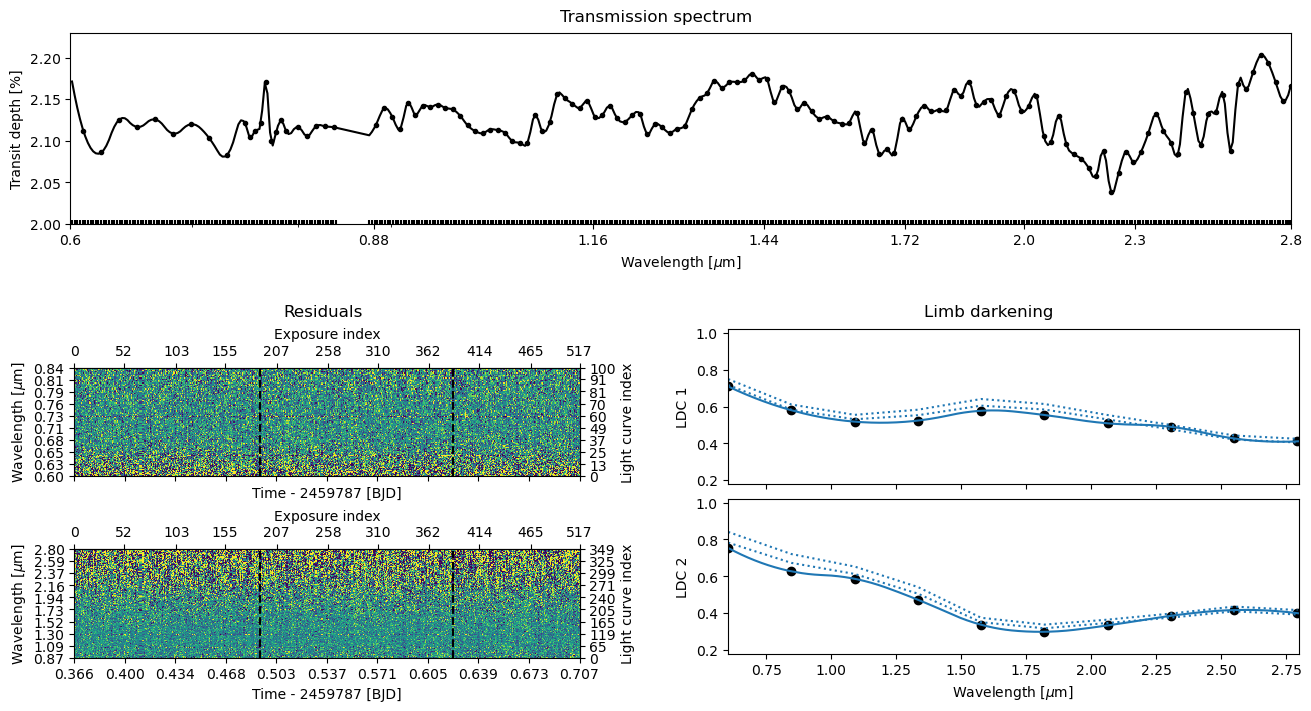
Posterior sampling#
Now we’re ready to continue with the posterior sampling. The sampler will automatically start from the parameter vector population clumped by the optimiser if we reset it using the ExoIris.reset_sampler method. If we wouldn’t do this, it would continue from the low-resolution model posterior sample. In theory, we could skip the optimisation step completely, but it’s better to run the optimiser at least for a bit after changing the radius ratio knots.
[14]:
ts.reset_sampler()
[15]:
ts.sample(1000, thin=100, repeats=5, pool=pool, lnpost=lnpostf)
[16]:
ts.plot_fit(result='mcmc', **pargs);
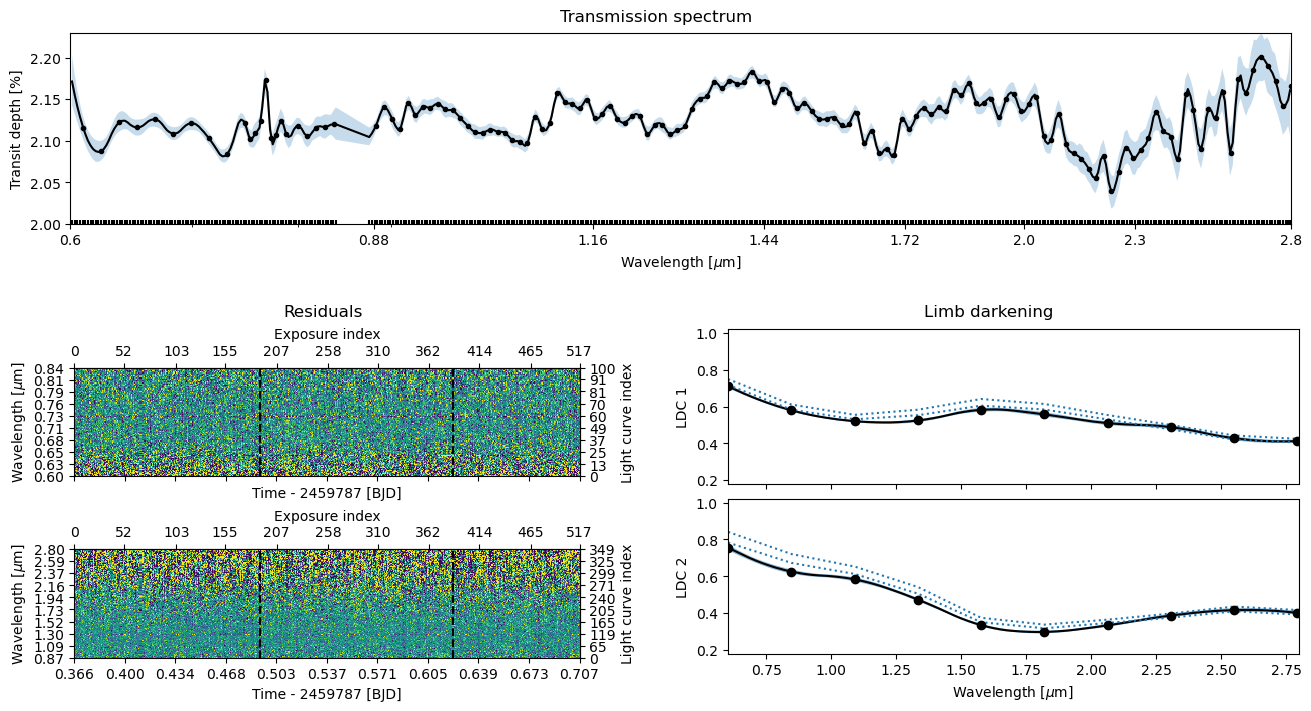
Save the results#
[17]:
ts.save(overwrite=True)
[18]:
pool.close()
©2025 Hannu Parviainen